Why GLLMM technology will never advance further toward true AI


There's a lot of nuance involved in understanding the general capabilities, benefits, and pitfalls of GLLMM tech; what it can do, what it's good for, and what it can't do, or is bad for. Unfortunately, as the landscape of social and personal opinion surrounding the tech and its use is so polarized, there's little room for that nuance to make its way into the general discussion.
There are many ethical concerns surrounding the way training data is collected, how authors, artists, and other human creators of that data are able to provide consent and receive compensation for its use, and how the technology is used to replace or supplant human labor, distill economic and sociopolitical power, and generally harm our information ecosystem and society at large. This post will address none of those. Instead, I aim to explain the fundamental flaws in the technology itself and its application in areas it is simply not and never will be suited for.
A Stochastic Inference Engine
All modern "AI" tech you see today falls into one of four categories, or some combination of them working together: The first and still most prevalent is simply bullshit marketing speak for simple algorithms or software that has existed for decades, but the people selling it want to ride the "AI" hype for more business so they call it AI. This isn't about that.
The second is general neural network machine learning systems in which a software algorithm iteratively "learns" via repeated random trial and result to zero in on a behavior that produces a desired result. This is the kind which does things like optimizing paths through a maze, breaking videogame speedrun records, or discovering novel solutions for problems given a set of defined outcome parameters in areas such as chemical synthesis, materials science, structural engineering, etc. These systems have their own set of benefits and limitations which are also outside the scope of this article.
The third is image generating models like Stable Diffusion. They train by iteratively deconstructing and reconstructing images in order to build a statistical model that can generate images that visually resemble those in its training set. Once again, these are outside the scope of this article.
This article is about the fourth category: Generative Large Language Models (GLLMs) or sometimes Multi-modal Models (GLLMMs) or just LLMs for short. These are essentially a grown up relative of the neural networks previously mentioned, except that they work with language tokens that simulate human written communication, and they are huge. They can be composed of billions of parameters, trained on datasets so large that they effectively reach the end of the internet and all digital recorded information (and misinformation) and run out of new things to intake.
The fundamental way in which LLMs work can be distilled down to the following: They train by intaking large chunks of information in the form of human-readable text, parse it into a series of 'tokens' representing different patterns, and store it as a multi-dimensional array of values representing the strength of correlations between those patterns. Then, when queried, it intakes a prompt string, parses it into a series of tokens representing the patterns in the prompt, compares them to the trained patterns and correlations stored in the model, and then uses the correlation data it has collected to statistically predict which other patterns most likely follow the ones provided by the prompt.
To a layperson or untrained eye, this sounds like it shouldn't work--after all, human language and communication is tremendously complex, and to distill it down to statistical correlations between patterns and then reconstruct something meaningful from that seems impossible. But, the model does produce something that looks like a real answer, so how can that be?
It turns out, that with sufficiently large data sets, it gets really uncanny how well it simulates a human response. It is after all trained on human produced data, although it's still only simulating that response. The response is not rooted in knowledge or understanding of fact, but rather in similarity to what we cognitively expect to follow based on our own experiences interacting with portions of the same or similar data sets. In order to fool our brains into believing we are interacting with an intelligent system and not just a stochastic parrot, the size of the token array and training dataset needs to be incomprehensibly vast.
Today's most impressive models are already running out of new data to train on, because they have consumed all there currently is to consume of human generated content on the internet. They are constantly scraping the internet for more data to train on, however, more and more of that data is now generated by those same models, and when models train on their own outputs, it creates a distortive feedback loop that ultimately leads to an output of gibberish, what researchers call model collapse.
The need for continually increasing amounts of 'pure' data to train the models is what ultimately limits them and defines their failure modes, but not necessarily for the reasons you might think. Because the output of the model is dependent on strength of correlations between input patterns reinforced through repeated input, it will always favor the most common probable response to queries, rather than the most accurate. After all, the model doesn't know what is accurate, only what it reads. You can test this by asking it about any commonly misunderstood information, and receiving the most commonly repeated misinformation. The more obscure and esoteric the subject, or the deeper it goes into the realm of true expertise, the less likely you are to get a correct response, because there is so little data of sufficient specialization and quality in its data set compared to the vast amount of everyday chatter, speculation, and misinformation.
The Dunning Kruginator 9000
If you have spent any significant amount of time on the internet, you have probably encountered some variation of this image:
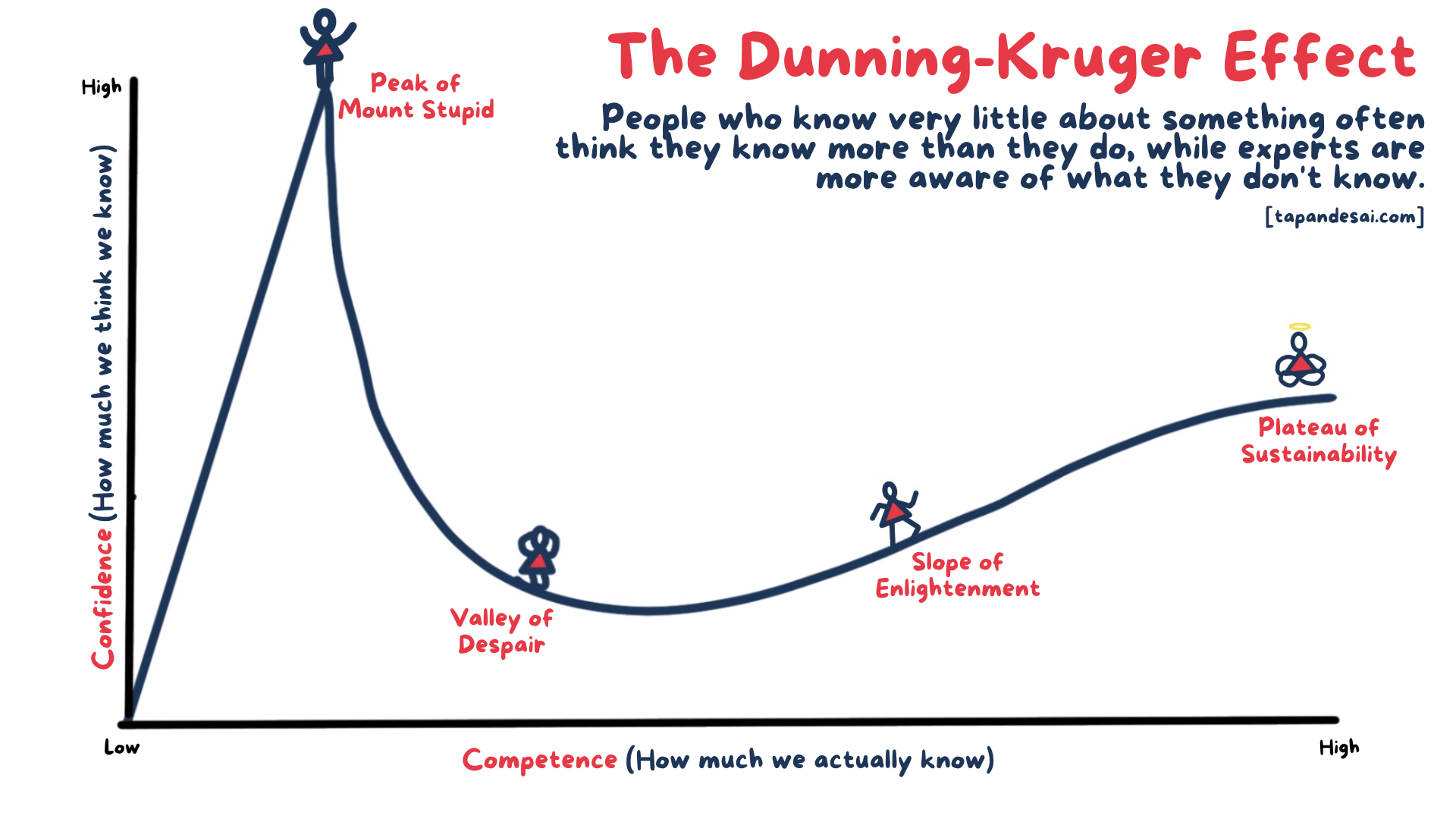
This is a classic depiction of the Dunning-Kruger effect, a cognitive bias that describes the systematic tendency of people with low ability in a specific area to give overly positive assessments of this ability (source: Wikipedia.)
One of the key outcomes of the Dunning-Kruger effect is that people with high confidence in their knowledge tend to be more engaged in posting online about what they know (or think they know) than people with true expertise, who have a greater understanding of the nuance and subtleties which might invalidate common misunderstandings. Because LLMs build their arrays of correlative values based on frequency of correlation between patterns, they will always generate outputs based on where confidence is highest, and where is confidence highest? At the 'Peak of Mount Stupid.'
This leads to an interesting observable phenomenon where the overwhelming public opinion of the suitability of LLMs for solving various problems tends to be "It's bad at what I do, as an expert, but good at things I'm less knowledgeable about." A vast majority of people when asked will earnestly believe that LLMs can replace the need for experts in other fields or areas of work, but that they are inadequate to do the work for which their own expertise is needed.
Put another way: people become good at things by specializing, and nobody is a specialist in all things. Therefore, they tend to be outliers in their level of knowledge of things within their subject of specialty, while being below average with respect to other specialists in the context of their own different subjects of specialty. LLMs, which generate a simulacrum of the level of expertise at that 'Peak of Mount Stupid' in all subjects appear competent to average people who are non-experts in any given subject.
Because LLMs are only a statistically constructed simulacrum of true intelligence, they can never advance beyond the average level of competence expressed in their source training data, and because high quality training data requires expertise and a lot of it, real human experts are needed to train specialized models in order for those models to simulate expert responses... but those responses can never be conclusively treated as fact, because unlike traditional expert systems where facts are meticulously recorded and entered into the dataset by experts to be later perfectly recalled, the LLM can only generate based on the correlative values it learned during the training process--nowhere in the LLM are stored the answers or responses themselves, only the statistical array of correlative values that can be used to imperfectly recreate a simulacrum of those answers based on past inputs.
In the end, it is a more costly, less efficient, and less reliable means of producing inferior results, but it does it at high speed and with the benefit of additional layers of cost and performance abstraction to meet arbitrary productivity metrics that ultimately benefit no one but the tech execs and shareholders seeking short term profits.
The AI industry lies, and the lying liars who tell them
The AI industry leaders, researchers, and CEOs know of these limitations, or else they are not qualified to speak on them, and yet, they keep insisting that if we just give them more time and money and resources to build up their great dream datacenters of massive scale for "next gen" AI, they will ultimately be able to create Artificial General Intelligence (or AGI, the new buzzword meant to denote 'true AI' in the classic scifi sense of intelligent thinking machines.) If they know this isn't the case, then why do they claim it is?
There are a couple reasons for this. One is that some of them are drinking their own kool-aid and getting high on their own supply, to the point that they've convinced themselves of this fantasy they so desperately want to be true. These are generally the CEOs and tech Venture Capitalists who need to justify their own commitment to the bit or else face the music that they bet on the wrong horse. A classic example of sunk cost fallacy.
The other is the grift. The industry is full of careless people with no morals who are always on the lookout for the next easy way to scam people out of their money. They did it with crypto, they did it with NFTs, and now the AI craze is just the latest bandwagon full of easy marks for fast cash. Many have an escape plan for when the bubble ultimately bursts, while others are just greedy and impulsive and genuinely don't think that far ahead--they just assume that if they can gain enough power and wealth from this grift before the shit hits the fan, that the consequences won't affect them. The unfortunate truth is that with the way things are currently going with regulatory capture and kleptocracy, they might be right.
The Bubble Will Burst
This is a bubble, and it will invariably burst when shareholder faith in the speculative market dries up and the massively overvalued companies promising AI advancement continue to fail to deliver on promises or return a profit to investors year after year. Big investors are growing increasingly desperate to drive adoption and engagement with their mediocrity machines, but it's not working, as real experts don't want it, and stuff built on the summit of Mount Stupid without the experts has a tendency to collapse in spectacular ways, eroding consumers' confidence and destroying trust and reputation built up over years by the corporations adopting it. Companies that invest too heavily in AI futures and speculation will pay the price, and so will everyone else due to the economic repercussions from the bubble burst. Companies like nvidia might come out ahead if they're fast enough to change gears when the time comes, as they've already profited from shipping the hardware up to this point.
The tip of the iceberg
All of this still doesn't even begin to touch on the myriad of other problems surrounding the current AI trend such as contested IPs and content rights, ethical concerns, poisoning of our information ecosystem, and model collapse. AI true believers and acolytes will try and trivialize or handwave away these problems as something that can be easily solved in the future, despite all evidence to the contrary. However, they can't escape the fact that the very core of this technology is fundamentally at odds with the promises they are making. It's not something they can fix. You can't get there from here, and those checks they're writing will never be cashed, because there never was anything to back the hype. LLMs are a dead-end in the search for a replacement for real human intelligence and decision making. They may continue to have niche utility here and there, and I have no doubt that continual improvements will be made in how they are integrated into other more robust and reliable systems, but nothing will change the fact that it's simply not the right technology for the job, and the illusion they've constructed to sell it as such will only hold up for so long.
LLMs are harmful in many other ways, and for further reading on why you personally should avoid using them wherever possible, I recommend this write up by cthos: LLMs are a Cognitohazard.
Stay critical until next time, and remember:
Only YOU can stop the A.I. nonsense.